빅데이터·인공지능은 ‘게임체인저’…활용방안 모색하는 중앙은행들
- ▲ 빅데이터와 인공지능 활용 방안에 대해 기업 뿐만 아니라 중앙은행과 경제학계도 큰 관심을 기울이고 있다. 학술 연구 뿐만 아니라 실제 경제 분석 및 예측에도 쓰이는 경우가 늘어나고 있다. /SAP 제공
GDP나우캐스팅은 두 가지 특징이 있다. 먼저 통상 분기 단위로 집계, 분석이 이뤄지는 GDP 및 관련 지표와 달리 ‘고빈도(high frequency)’에 해당하는 1주일 단위로 전망치를 내놓고 있다는 것이다. 고빈도 자료는 각각의 시기마다 발생하는 사건들 때문에 ‘잡음’이 많고, 이를 걸러내기도 어렵다. 수십 종의 자료를 동시에 살피면 정확한 경제 지표 변화를 분석할 수 있다는 자신감이 GDP나우캐스팅 서비스에 깔려있는 것이다. 두 번째는 경제 예측 과정이 사전에 입력된 예측 모형에 의해 자동화돼있다는 것이다. 경제학자들은 마치 소프트웨어 엔지니어처럼 사후적으로 예측 모형을 손질하는 역할을 맡는다. 뉴욕 FRB는 보고서에서 “이용 가능한 광범위한 범위의 거시경제 자료를 결합해 GDP성장률에 대한 조기 예측치를 만들어낼 수 있는 혁신적인 기법”이라고 적기까지 했다.
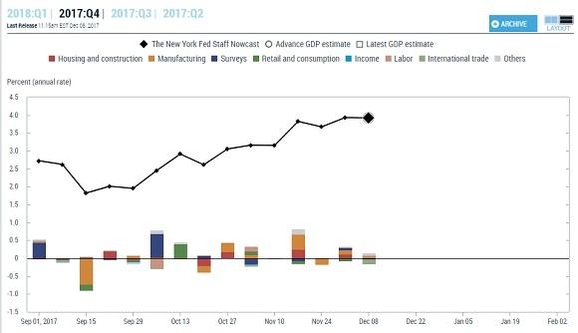
- ▲ 미국 뉴욕 연방준비은행이 운영하는 ‘GDP나우캐스팅’은 1주일 간격으로 각종 경제 정보를 반영해 분기 경제성장률 전망치와, 각 부문별 기여를 함께 보여준다. /뉴욕 연방준비은행
IMF(국제통화기금)는 9월 발간한 ‘빅데이터: 잠재력, 도전, 통계학적 함의(Big Data : Potential, Challenges and Statistical Implications)’ 보고서에서 “’빅데이터’는 단순한 유행어가 아니다”며 “바로 지금 여기에 존재하고 있다”고 썼다. “이미 민간 기업에서 분석 능력을 제고하기 위한 혁신 기법으로 광범위하게 채택되고 있다”는 게 IMF의 설명이다.
실제로 글로벌 금융투자업계에서는 인터넷 사용 기록, 신용카드 결제 기록, 위치정보, 위성 사진 등 다양한 종류의 빅데이터를 ‘대안적 데이터(alternative data)’라고 부르면서 투자 의사 결정에 활용하는 경우가 늘고 있다. 가령 8월초 미국 스포츠용품 전문기업 언더아머 주가가 실적 악화로 폭락했는데, 상당수 헤지펀드들이 이를 대안적 데이터를 활용해 미리 예측해 화제가 되었다. 직원 채용 공고 감소, 회사 평판 서비스 글래스도어 내에서 언더아머 CEO(최고경영자)에 대한 ‘별점(평판 점수)’ 하락, 인터넷 쇼핑몰에서 언더아머 제품 판매가격 추이 등을 보고 실적 악화에 베팅했다는 것이다.
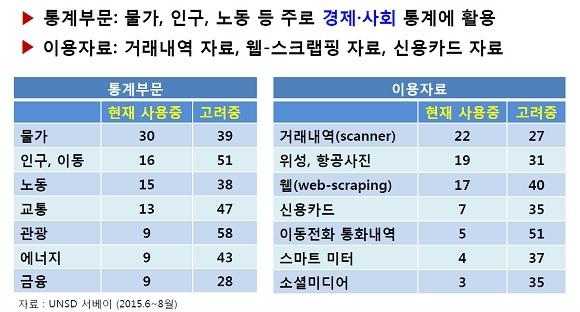
- ▲ 해외 정부 통계 담당 부서 및 중앙은행의 빅데이터 사용 현황. /한국은행
두 번째는 통계 자료를 작성하는 데 상당한 시간이 걸리는 문제를 보완할 수 있다는 것이다. 미 상무부 산하 경제분석국(BEA)은 7월 신용카드 결제 자료를 활용해 개인소비지출 추이를 분석한 보고서를 발표했다. BEA는 여기서 특성 의류나 스포츠용품 브랜드 유행이 어떻게 퍼져나가는 지를 보이기도 했다. 마지막으로 공식 통계를 작성하는 데 쓰일 수 있는 새로운 자료를 제공해줄 수 있다고 IMF는 봤다. 가령 네덜란드의 경우 온라인 쇼핑몰 판매 기록을 소비자물가지수 작성에 반영하고 있다.
미국 등 선진국 경제학계에서 빅데이터를 활용한 경제 분석은 3~4년 전부터 활발히 진행되고 있다. 아티브 미안 프린스턴대 교수는 2013년 계간경제학회보(QJE)에 발표한 ‘가계 대차대조표, 소비, 경제 불황’이란 제목의 논문에서 2005년부터 2009년까지 미국 내 마스터카드 사용 기록을 카운티(시군구급 지방자치단체)별, 소비항목별로 집계한 자료를 활용했다. 이를 우편번호별 주택 평균 가격 미시 자료와 연계, 2008년 글로벌 금융위기 전후 주택 가격 변동이 실제 소비에 미치는 영향을 분석했다.
하지만 빅데이터를 활용한 경제 분석은 아직은 시험 단계이다. 국제결제은행(BIS)이 37개 나라 중앙은행을 대상으로 조사한 결과에 빅데이터 기반 자료를 핵심 통계 자료로 쓰고 있는 곳은 8개 국가에 불과했다. 11곳은 보조지표로 17곳은 단순 연구 수준에 머물러 있었다.
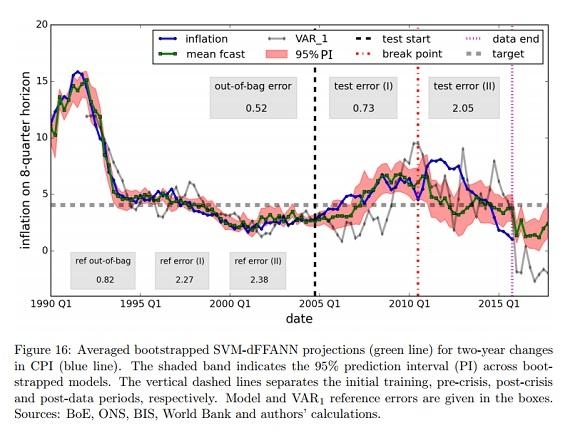
- ▲ 영국은행 연구팀이 물가상승률 예측에 인공지능 기반 기계학습을 사용한 결과. 파란선이 실제 물가상승률이고 녹색선이 예측치다. 회색선은 일반적인 경제학 모형인 VAR(벡터자기회귀)를 사용한 예측치. /영국은행
한편 인공지능(AI)을 활용한 기계학습(머신러닝)을 사용해 경제 현상을 분석, 예측하려는 시도도 경제학계와 중앙은행에서 이뤄지고 있다. AI에게 경제 현상에 대한 자료를 주고, 알아서 학습하도록 한 뒤에 그 결과를 활용하자는 것이다. 마치 알파고(AlphaGo)가 둔 바둑을 해석해 이를 바탕으로 바둑 이론을 발전 시키자는 얘기와 비슷하다. 영상이나 음성 자료 등을 분석하기 위해서는 기계학습 기법을 도입해야 하기 때문에 빅데이터와 인공지능 활용은 궤를 같이하는 측면도 존재한다. 에드워드 글레이저 미 하버드대교수 등이 2016년 발표한 ‘빅데이터와 대도시(Big Data and Big Cities: The Promises and Limitations of Improved Measures of Urban Life)’ 논문에서 구글의 ‘스트리트뷰’ 길거리 영상을 기계학습을 이용해 분석했었다.
영란은행(Bank of England)은 9월 ‘중앙은행에서의 기계학습(Machine learning at central banks)’ 보고서에서 기계학습 기법을 이용한 AI의 예측 능력이 기존 경제학 모형의 예측보다 뛰어났다는 결과를 내놨다. 영란은행은 ▲과거 거시경제 변수들을 가지고 소비자물가지수 변화를 예측하고 ▲은행 재무제표를 이용해 은행 건전성 이상 징후를 탐지하며 ▲금융산업에서 IT 기술에 바탕을 둔 초대형 벤처기업(유니콘)이 등장하는 패턴을 파악하는 데 각각 머신러닝을 활용한 결과 이런 결론이 나왔다고 소개했다. 특히 많은 거시경제 변수들을 ‘입력’해 그 상관관계를 학습하게 한 뒤, GDP나 물가지수 등 핵심 경제여건 변화를 예측하는 기법은 거시 경제 이론의 ‘판’을 흔들 수 있는 잠재력이 있다. 현재 거시 경제 예측 모형의 핵심 문제가 경제 변수들 간의 인과관계를 어떻게 ‘판별(identification)’할 수 있느냐기 때문이다. 한 한은 금통위원은 “현재 거시경제 예측 모형에 문제가 많은 상황이라 기계학습 기반 기법의 예측력이 뛰어다나면 향후 상당한 잠재력이 있을 것”이라고 말했다.
센딜 멀레이너선(Sendhil Mullainathan) 미 하버드대 교수는 올해 4월 ‘경제학 전망 회보(Journal of Economic Perspectives)’에 게재한 ‘기계학습: 응용계량경제학적 접근(Machine Learning: An Applied Econometric Approach)’ 논문에서 기계학습이 경제학자들에게 유용한 도구가 될 수 있다는 의견을 내놨다. 먼저 사람들의 대화나 영상, 신문 기사 등을 쉽게 가공해 경제 분석에 활용할 수 있다. 두 번째로 기계학습을 통해 많은 경제 변수들 간 상관관계를 정확히 파악해서 이를 모형 구축에 활용할 수 있다는 것이다. 세 번째는 인공지능을 통해 병을 진단하고, 가석방 심사 전 재범률 예상에 활용하는 것처럼 경제 모형을 시뮬레이션해 결과를 예상하는 데 활용할 수 있다는 게 멀레이너선 교수의 설명이다. 마지막으로 전통적인 자료 분석 과정에서 놓치게 되는 부분을 보완할 수 있다는 게 그의 시각 이다. 가령 설문조사 자료에서 무응답은 그저 무응답으로 간주되지만, 기계학습을 이용하면 왜 설문조사에 응하지 않았는지 대규모 자료를 분석해 답을 낼 수 있다는 얘기다.
원문보기:
http://biz.chosun.com/site/data/html_dir/2017/12/10/2017121000439.html#csidxbe3f09d04ee252fbd061bb55a389d9e
 (조선비즈)
(조선비즈)'IT & Insight > IT News' 카테고리의 다른 글
| '가상화폐+주택공유' 합성한 크립토비앤비 내년 서비스 개시 (0) | 2017.12.14 |
|---|---|
| 인간과 인공지능, 이번엔 본능적 순발력 대결 (0) | 2017.12.14 |
| 빅데이터·AI 기술활용, 범죄 미리 알고 예방하는 시대 오나 (0) | 2017.12.13 |
| 2018년 인공지능·빅데이터·블록체인 기술 활용 본격화…사이버 보안 위협은 커져 (0) | 2017.12.12 |
| [가상화폐 규제] "가상화폐는 일부분…블록체인 주목해야" (0) | 2017.12.12 |